Actions
Link checker¶
Introduction¶
The Link Checker script is to help you identify and manage broken links and images on a website. It automates the process of checking URLs within a specified domain and provides detailed reports on the status of each link and image.
Script destination¶
script location: extension/Resources/Public/scripts
script Name: web_crawler.py
Usage¶
Configuration¶
Before using the Link Checker script, you need a configuration file "conf.json".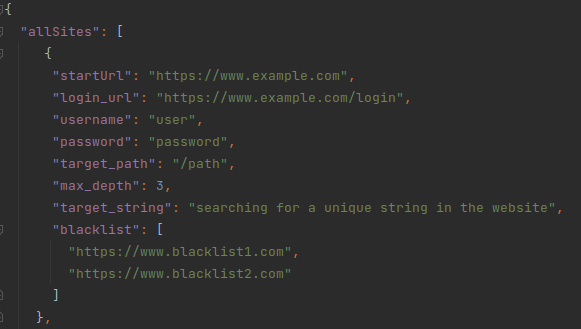
- "startUrl": The URL where the link checking will begin.
- "login_url": URL for logging in if required. If empty it will use the "startUrl" instead.
- "username and password": Login credentials. If you don't have login credentials, leave this field empty it's important !
- "max_depth": The maximum depth to crawl links.
- "target_path": The path to restrict link checking (e.g., /blog).
- "target_string": Looking for a unique string.
- "blacklist": URLs to exclude from checking.
Ignore CSS class¶
This script also ignore the CSS class "link-checker-skip"
Running the Script¶
You can run the Link Checker script using the following command:
python web_crawler.py conj.json "all or <index>"
Result/Output¶
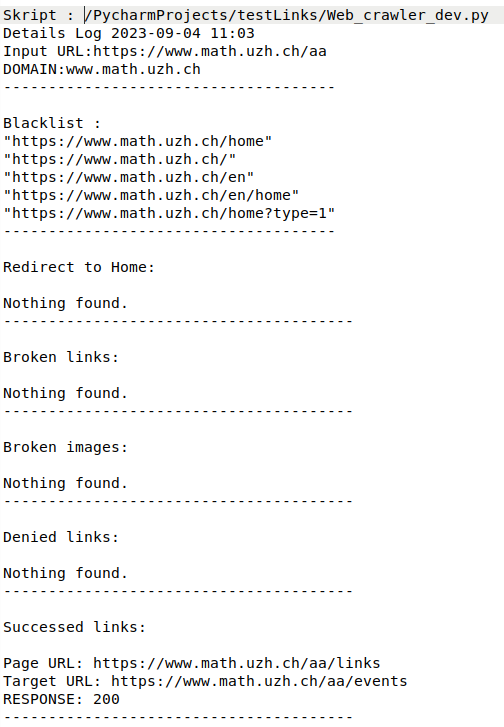
It generate detailed reports. These reports include:- Broken links and images with response codes.
- Denied links with 403 Forbidden errors.
- Redirects to the home page.
- Successfully checked links.
- The results will be saved in log files (detail.log and summary.log) and a CSV file containing broken links.
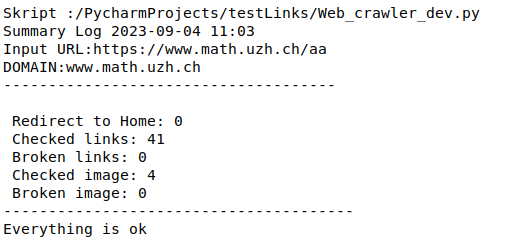
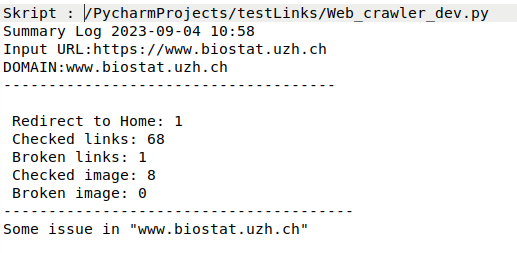
Summary log:¶
0 error
1 or more error
Detail log:¶
Updated by Zhoujie Li 5 months ago · 11 revisions